
“The boy saw the man with the telescope.” What does this sentence mean to you—that the boy viewed the man through a telescope, or that the boy saw a man holding a telescope?
Language is full of ambiguities just like this one. But if they can cause confusion even among human speakers, how will a large language model—the machine learning paradigm responsible for the likes of ChatGPT—handle them? And what are the consequences if it can’t?
A multidisciplinary team of Johns Hopkins University researchers—including Benjamin Van Durme, an associate professor of computer science, and Kyle Rawlins, an associate professor of cognitive science—investigated these questions in the context of semantic parsing, the process of taking natural language and turning it into executable code. They will present their findings at the 12th International Conference on Learning Representations in May.
“Language is notoriously riddled with ambiguity,” says Elias Stengel-Eskin, Engr ’23 (PhD), one of the investigators on the team. “Most of the time it doesn’t cause us a lot of problems, but even with human speakers, we see ambiguities leading to communication breakdowns.”
Luckily, humans can usually clarify their intentions pretty quickly. But that may not be the case for a virtual assistant or a robot that uses semantic parsing to understand a user’s commands.
“We can’t be expected to never give robots ambiguous instructions,” says Stengel-Eskin. “Instead, we should design them to handle ambiguity gracefully—by asking clarification questions or asking for confirmation if an instruction is ambiguous.”
The researchers decided to test existing large language models’ ability to recognize ambiguity in the first place. They found that most existing semantic parsing data does not contain explicit ambiguity, so they created their own data by identifying five common types of linguistic ambiguity:
- Prepositional phrase attachment: Our original example, “The boy saw the man with the telescope,” can be interpreted as the boy seeing a man through a telescope OR as the boy seeing a man who is holding a telescope;
- Scope ambiguity: “Every person saw a dog” can mean that everyone saw the same dog OR that everyone saw some dog, but that there could be multiple different dogs;
- Inverse scope: “A person pets every cat” can mean that a single person pets every cat OR that there might be more than one person petting each cat, just so long as every cat gets pet;
- Conjunction bracketing: “The woman walked and ate or drank”—here we don’t know if she walked and ate . . . or she drank OR if she walked and then either ate or drank; and
- Pronoun coreference: “The man saw Harry and he spoke”—because both the man and Harry ostensibly have the same gender pronoun, we don’t know whom “he” refers to.
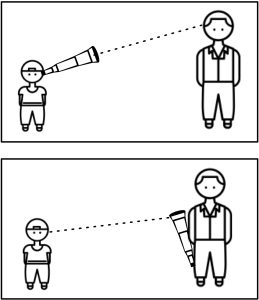
An example of prepositional phrase attachment ambiguity. The statement is compatible with two possible interpretations, represented visually: “The boy saw the man with the telescope.”
The team then tested language models, including OpenAI’s gpt-3.5-turbo, to see how they performed when parsing this kind of ambiguous language and whether they could even recognize that it could have multiple possible interpretations.
The researchers found that “zero-shot” prompting—or not giving the models any direct examples of ambiguous language being interpreted in different ways—caused the models to do pretty poorly on recognition and parsing tasks.
“They were either unable to do it at all or they could parse one interpretation but not the other,” Stengel-Eskin reports.
But with “few-shot” training—giving the models explicit evidence and explanations of linguistic ambiguity—the team found that the models were in fact able to recognize a given sentence’s ambiguity and capture its different interpretations. The researchers say this finding is promising because it provides evidence that language models can handle ambiguity relatively well—if it’s present in the training data.
“Right now, most datasets actually avoid ambiguity because they optimize for annotator agreement,” Stengel-Eskin explains. “That means when data is collected, we mostly treat the cases where human annotators disagree as ‘noise’ and generally assume that one annotator made a mistake—not that they both interpreted the same sentence differently, but still correctly.”
This black-and-white thinking can hurt models’ ability to learn ambiguity, the researchers say. They advocate for future data annotation to be performed in a way that allows people to flexibly express their preferences, thus capturing the natural ambiguity in spoken and written language for language models to learn.