Putting An End to End-to-End: Gradient-Isolated Learning of Representations#
Authors: Sindy Löwe, Peter O’Connor, Bastiaan S. Veeling
Affiliations: AMLab
NeurIPS 2019
Links: arXiv
Summary#
The authors propose a novel deep learning method for local self-supervised representation learning that does not require labels nor end-to-end backpropagation but exploits the natural order in data instead. The authors demonstrate that the representations created by the top module yield highly competitive results on downstream task classification tasks in the audio and visual domain.
Key Ideas#
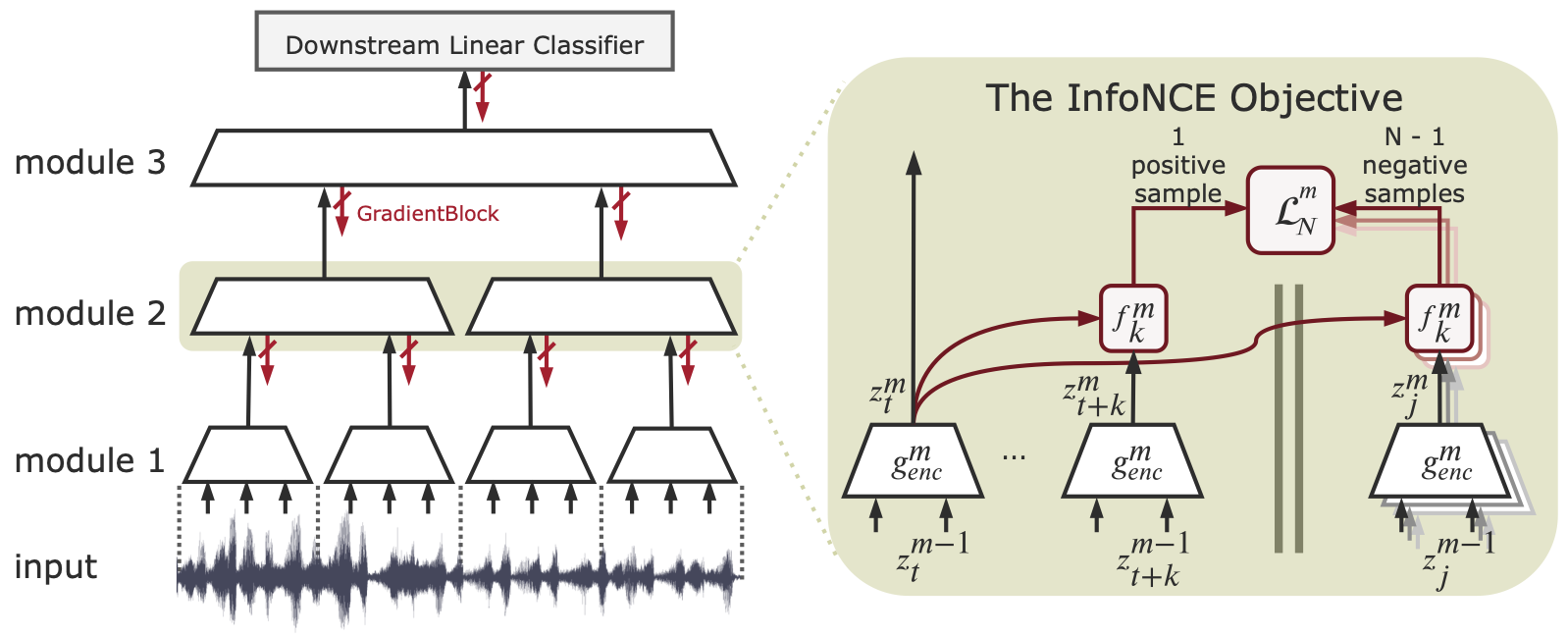
Greedy InfoMax (GIM). The authors propose a novel approach for self-supervised representation learning: Greedy InfoMax (GIM). Given a CNN architecture, we split it by depth into a stack of \(M\) modules. Each encoding module \(g_\text{enc}^m\) maps the output from the previous module to an encoding \(z_t^m = g_\text{enc}^m(\text{GradientBlock}(z_t^{m-1}))\). We train each module \(g_\text{enc}^m\) using the module local InfoNCE loss:
Technical Details#
Group of 4 image patches that excite a specific neural at 3 levels in the model.

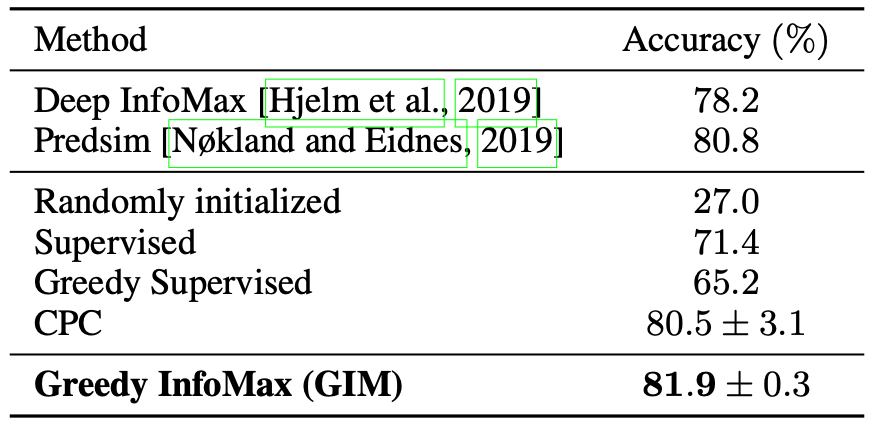
STL-10 classification results on the test set.