Magic3D: High-Resolution Text-to-3D Content Creation#
Authors: Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, Tsung-Yi Lin
Affiliations: NVIDIA
Links: Project Page, arXiv
Summary#
Key Ideas#
Magic3D is a two-stage coarse-to-fine framework that uses efficient scene models that enable high-resolution text-to-3D synthesis.
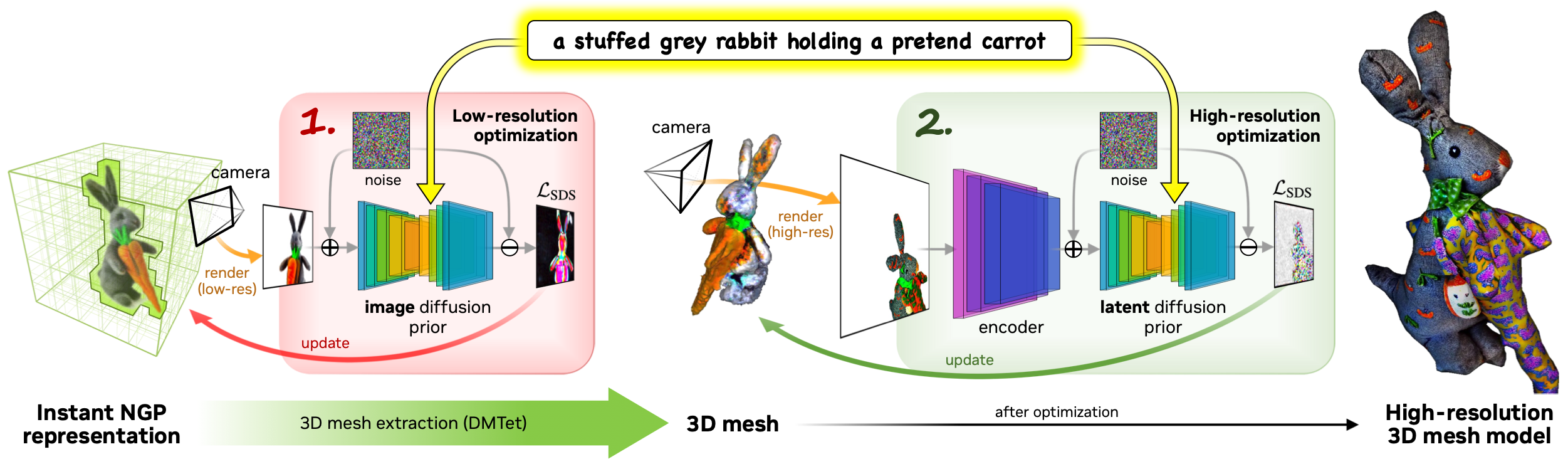
Coarse-to-fine diffusion priors. In the first stage, the authors use the base diffusion model in eDiff-I [1]. This diffusion prior is used to compute gradients of the scene model via a loss defined on rendered images at a low resolution
Coarse scene model. The initial coarse state of the optimization requires finding the geometry and textures from scratch. This is challenging as we need to accomodate complex topological changes in the 3D geometry and depth ambiguities from 2D supervision. Mip-NeRF 360 [3] is computationally expensive as it is based on a large global coordinate-based MLP.
The authors adopt the hash grid encoding from Instant NGP [4], which allows to represent high-frequncy details at a much lower computational cost. Two single-layer neural networks are used, one predicting albedo and density and the other one predicting normals.
Fine scene model. Rendering textured meshes with differentiable rasterization can be performed efficiently at very high resolutions. The authors use textured 3D meshes from DMTet [5] as the scene representation. Using the neural field from the coarse stage as the initialization for the mesh geometry, we can also sidestep the difficulty of learning large topological changes in meshes.

Coarse-to-fine optimization. Similar to Instant NGP [4], the authors optimize the neural field in the coarse stage. Instead of estimating normals from density differences, they use an MLP to predict the normals, which helps to significantly reduce the computational cost of optimizing the coarse model.
In the fine mesh optimization stage, the authors initialize the DMTet SDF with the neural field. When rendering the meshes, they also increase the focal length to zoom in on object details, which helps to recover high-resolution details. To encourage smoothness of the surface, they further regularize the angular differences between adjacent faces on the mesh.
Technical Details#
Notes#
References#
[1] Y. Balaji, S. Nah, X. Huang, A. Vahdat, J. Song, K. Kreis, M. Aittala, T. Aila, S. Laine, B. Catanzaro, T. Karras, M. Liu. eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers. In arXiv, 2022.
[2] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, B. Ommer. High-resolution image synthesis with latent diffusion models. In CVPR, 2022.
[3] J. Barron, B. Mildenhall, D. Verbin, P. Srinivasan, P. Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. In CVPR, 2022.